The documentation you are viewing is for Dapr v1.9 which is an older version of Dapr. For up-to-date documentation, see the latest version.
Actors overview
Introduction
The actor pattern describes actors as the lowest-level “unit of computation”. In other words, you write your code in a self-contained unit (called an actor) that receives messages and processes them one at a time, without any kind of concurrency or threading.
While your code processes a message, it can send one or more messages to other actors, or create new actors. An underlying runtime manages how, when and where each actor runs, and also routes messages between actors.
A large number of actors can execute simultaneously, and actors execute independently from each other.
Dapr includes a runtime that specifically implements the Virtual Actor pattern. With Dapr’s implementation, you write your Dapr actors according to the Actor model, and Dapr leverages the scalability and reliability guarantees that the underlying platform provides.
When to use actors
As with any other technology decision, you should decide whether to use actors based on the problem you’re trying to solve.
The actor design pattern can be a good fit to a number of distributed systems problems and scenarios, but the first thing you should consider are the constraints of the pattern. Generally speaking, consider the actor pattern to model your problem or scenario if:
- Your problem space involves a large number (thousands or more) of small, independent, and isolated units of state and logic.
- You want to work with single-threaded objects that do not require significant interaction from external components, including querying state across a set of actors.
- Your actor instances won’t block callers with unpredictable delays by issuing I/O operations.
Actors in dapr
Every actor is defined as an instance of an actor type, identical to the way an object is an instance of a class. For example, there may be an actor type that implements the functionality of a calculator and there could be many actors of that type that are distributed on various nodes across a cluster. Each such actor is uniquely identified by an actor ID.
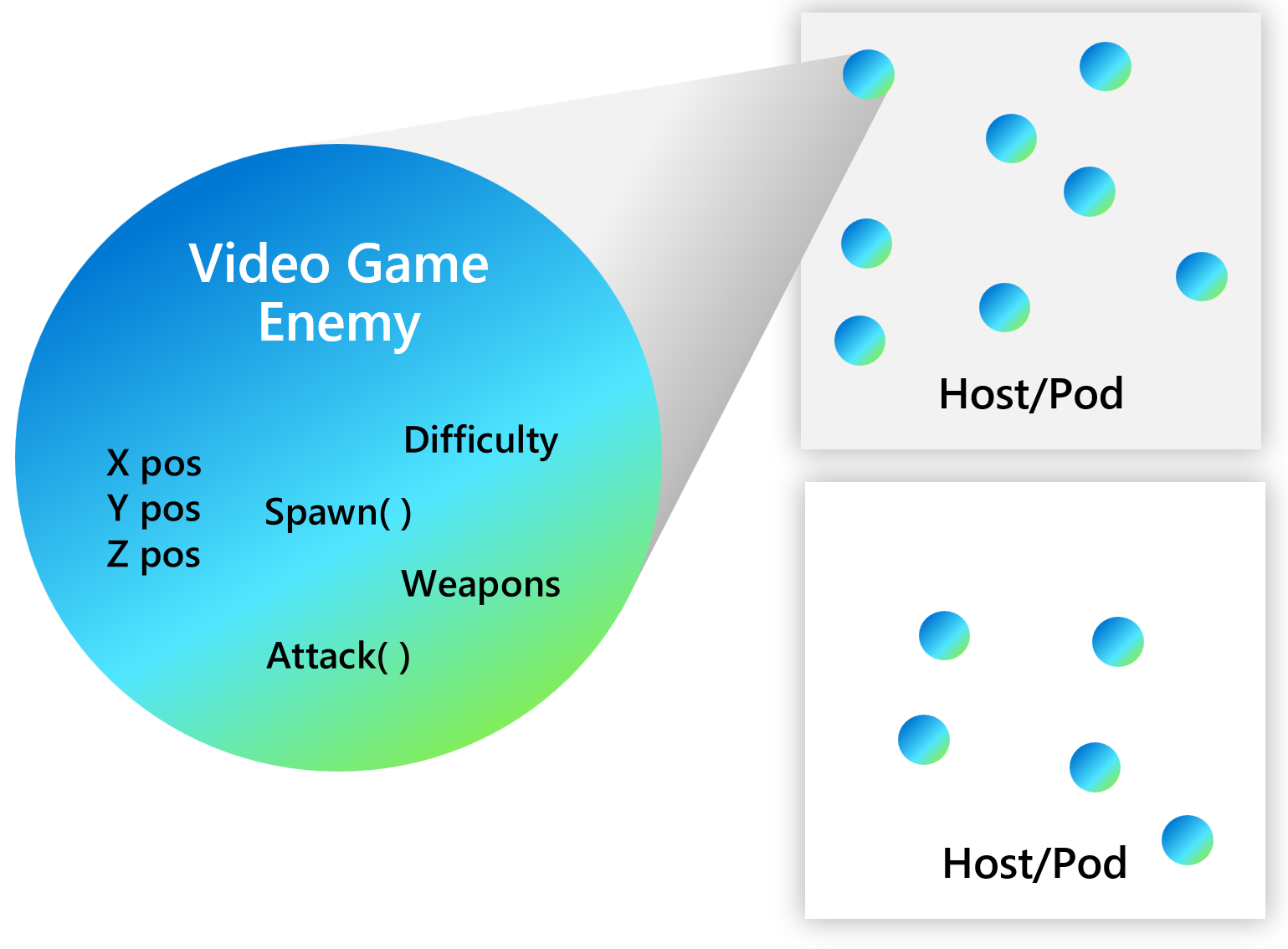
Actor lifetime
Dapr actors are virtual, meaning that their lifetime is not tied to their in-memory representation. As a result, they do not need to be explicitly created or destroyed. The Dapr actor runtime automatically activates an actor the first time it receives a request for that actor ID. If an actor is not used for a period of time, the Dapr actor runtime garbage-collects the in-memory object. It will also maintain knowledge of the actor’s existence should it need to be reactivated later.
Invocation of actor methods and reminders reset the idle time, e.g. reminder firing will keep the actor active. Actor reminders fire whether an actor is active or inactive, if fired for inactive actor, it will activate the actor first. Actor timers do not reset the idle time, so timer firing will not keep the actor active. Timers only fire while the actor is active.
The idle timeout and scan interval Dapr runtime uses to see if an actor can be garbage-collected is configurable. This information can be passed when Dapr runtime calls into the actor service to get supported actor types.
This virtual actor lifetime abstraction carries some caveats as a result of the virtual actor model, and in fact the Dapr Actors implementation deviates at times from this model.
An actor is automatically activated (causing an actor object to be constructed) the first time a message is sent to its actor ID. After some period of time, the actor object is garbage collected. In the future, using the actor ID again, causes a new actor object to be constructed. An actor’s state outlives the object’s lifetime as state is stored in configured state provider for Dapr runtime.
Distribution and failover
To provide scalability and reliability, actors instances are distributed throughout the cluster and Dapr automatically migrates them from failed nodes to healthy ones as required.
Actors are distributed across the instances of the actor service, and those instance are distributed across the nodes in a cluster. Each service instance contains a set of actors for a given actor type.
Actor placement service
The Dapr actor runtime manages distribution scheme and key range settings for you. This is done by the actor Placement service. When a new instance of a service is created, the corresponding Dapr runtime registers the actor types it can create and the Placement service calculates the partitioning across all the instances for a given actor type. This table of partition information for each actor type is updated and stored in each Dapr instance running in the environment and can change dynamically as new instance of actor services are created and destroyed. This is shown in the diagram below.
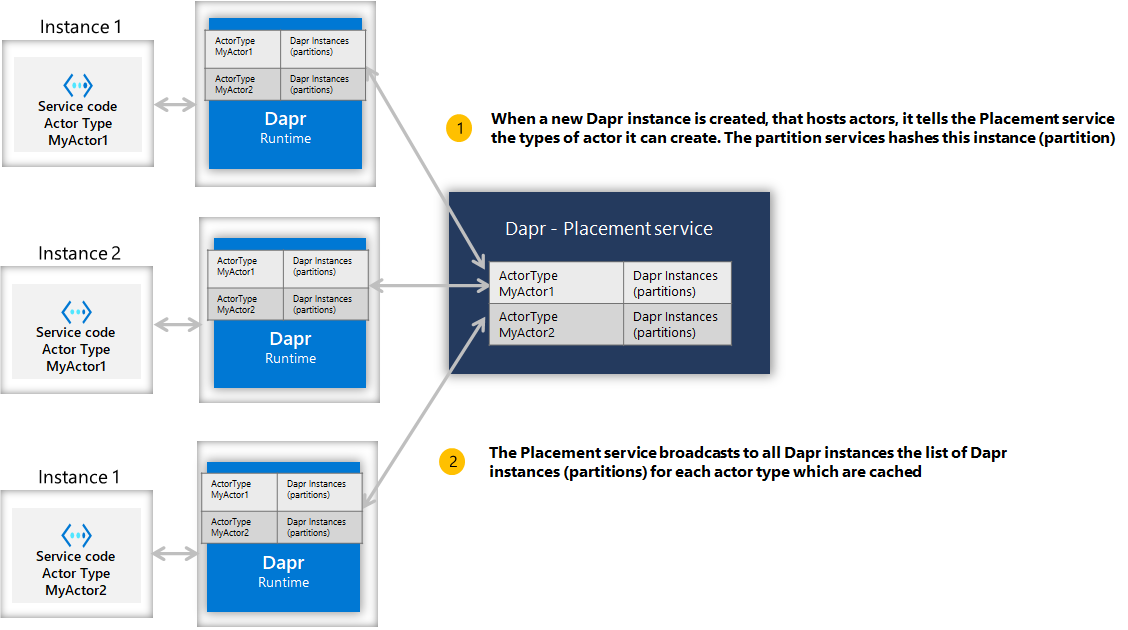
When a client calls an actor with a particular id (for example, actor id 123), the Dapr instance for the client hashes the actor type and id, and uses the information to call onto the corresponding Dapr instance that can serve the requests for that particular actor id. As a result, the same partition (or service instance) is always called for any given actor id. This is shown in the diagram below.
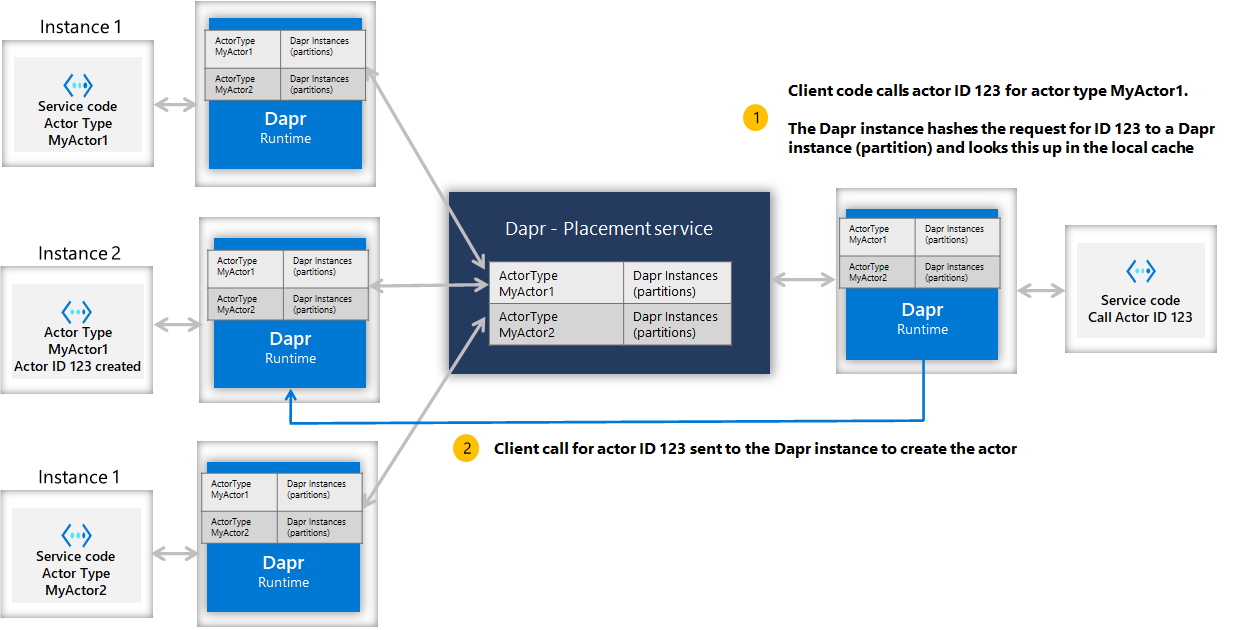
This simplifies some choices but also carries some consideration:
- By default, actors are randomly placed into pods resulting in uniform distribution.
- Because actors are randomly placed, it should be expected that actor operations always require network communication, including serialization and deserialization of method call data, incurring latency and overhead.
Note: The Dapr actor Placement service is only used for actor placement and therefore is not needed if your services are not using Dapr actors. The Placement service can run in all hosting environments, including self-hosted and Kubernetes.
Actor communication
You can interact with Dapr to invoke the actor method by calling HTTP/gRPC endpoint.
POST/GET/PUT/DELETE http://localhost:3500/v1.0/actors/<actorType>/<actorId>/<method/state/timers/reminders>
You can provide any data for the actor method in the request body, and the response for the request would be in the response body which is the data from actor call.
Another, and perhaps more convenient, way of interacting with actors is via SDKs. Dapr currently supports actors SDKs in .NET, Java, and Python.
Refer to Dapr Actor Features for more details.
Concurrency
The Dapr actor runtime provides a simple turn-based access model for accessing actor methods. This means that no more than one thread can be active inside an actor object’s code at any time. Turn-based access greatly simplifies concurrent systems as there is no need for synchronization mechanisms for data access. It also means systems must be designed with special considerations for the single-threaded access nature of each actor instance.
A single actor instance cannot process more than one request at a time. An actor instance can cause a throughput bottleneck if it is expected to handle concurrent requests.
Actors can deadlock on each other if there is a circular request between two actors while an external request is made to one of the actors simultaneously. The Dapr actor runtime automatically times out on actor calls and throw an exception to the caller to interrupt possible deadlock situations.
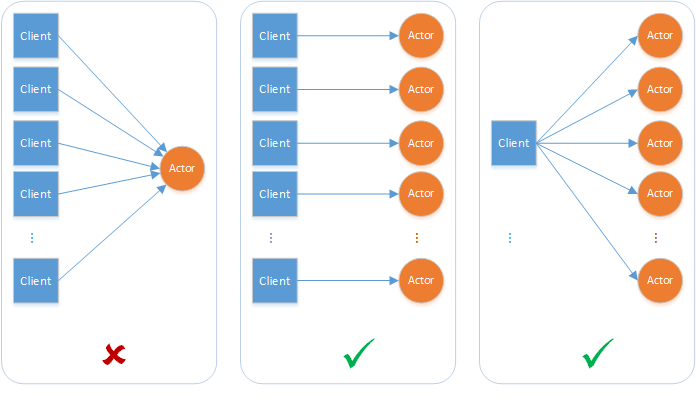
Reentrancy
As an enhancement to the base actors in dapr, reentrancy can now be enabled as a preview feature. To learn more about it, see actor reentrancy
Turn-based access
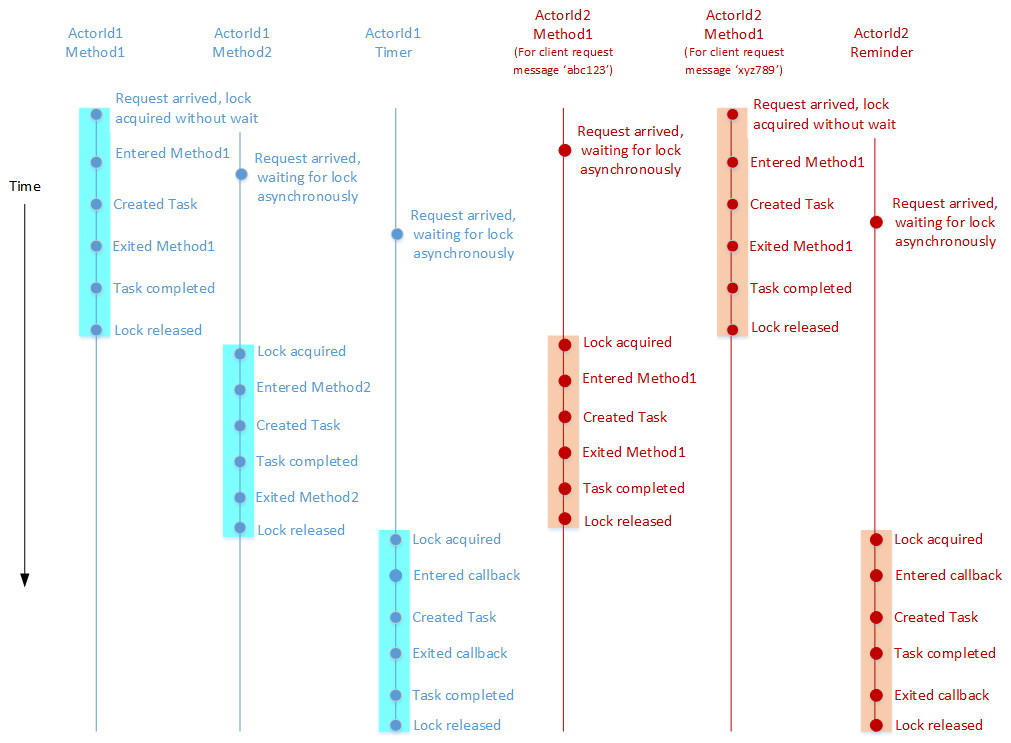
A turn consists of the complete execution of an actor method in response to a request from other actors or clients, or the complete execution of a timer/reminder callback. Even though these methods and callbacks are asynchronous, the Dapr actor runtime does not interleave them. A turn must be fully finished before a new turn is allowed. In other words, an actor method or timer/reminder callback that is currently executing must be fully finished before a new call to a method or callback is allowed. A method or callback is considered to have finished if the execution has returned from the method or callback and the task returned by the method or callback has finished. It is worth emphasizing that turn-based concurrency is respected even across different methods, timers, and callbacks.
The Dapr actor runtime enforces turn-based concurrency by acquiring a per-actor lock at the beginning of a turn and releasing the lock at the end of the turn. Thus, turn-based concurrency is enforced on a per-actor basis and not across actors. Actor methods and timer/reminder callbacks can execute simultaneously on behalf of different actors.
The following example illustrates the above concepts. Consider an actor type that implements two asynchronous methods (say, Method1 and Method2), a timer, and a reminder. The diagram below shows an example of a timeline for the execution of these methods and callbacks on behalf of two actors (ActorId1 and ActorId2) that belong to this actor type.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.